
CS 246 Notes
CS246 Object-Oriented Software Dev
OOP from three perspectives:
- Programmer’s perspective - How to structure programs correctly, how to lower the risk of bugs.
- Compiler’s perspective - What do our constructors actually means, and what must the compiler do to support them.
- Designer’s perspective - How to use OOP tools (encapsulation, inheritance, polymorphism, etc.) to build systems.
Introduction
Comparison between C and C++:
C:
1 |
|
C++:
1 | import <iostream>; |
Note:
import, like
#include, brings names and definitions from other files, libraries, or module into our code.import, was C++’s new module system, more about modules in future lectures.#include <iostream>works. However module system is preferred in CS 246.
function
main()must return int,void main() {...}is not legal in C++return statement returns a status code to OS
- can be omitted from main-default to
return 0;
- can be omitted from main-default to
coutand<<are how you write to stdout.- this is the preferred way to do I/O in C++
- stdio.h and printf are still available in C++
using namespace std- called a using directive
- C++ organizes names into namespaces
- without
using namespace std, you need to writestd::cout << "Hello World" << std::endl
most C programs work in C++ (or minimal changes is required)
Input/Output
Basic Info
C++ comes with 3 built-in I/O streams:
cout - for writing to stdout
cerr - for writing to stderr
cin - for reading from stdin
Built-in Operators:
<< “put to”, insertion operator (output)
>> “get from”, extraction operator (input)
<<
1 | cout << ____ << ____ << ____ << endl; |
[^]: dates, expressions, literals
[^]: endl outputs an end of line char, and flushes the output buffer.
1 | cout << X // Operator "point" in the direction of data flow |
Example: Read 2 ints and print their sum
1 | import <iostream>; |
Note:
- The
>>operator tries to interpret the input data, according to the type of variable being read into.- In this case, x is an int, so >> will expect to read chars that look like an int: “123” or “-42” and assemble those chars into an int value.
- it’ll stop reading when it sees a character that is not part of an integer (letter or space)
cin >>ignores leading whitespaces (spaces, tabs, newlines)- when reading from the keyboard, the program will pause waiting for the user input.
- pressing Enter causes the entered text to be submitted to the program
- pressing ^D signals end of file, or end of input
What if bad things happen?
input doesn’t contain an int
input is too large to fit in the variable
input is exhausted (not enough data) and get 2 ints
The input operation fails, how can we test for this in our program?
if read failed (for whatever reasons):
cin.fail()will return trueif EOF:
cin.eof()will also return trueBut not until attempted read fails
Example: read all int from stdin, echo to stdout, one per line, stop at EOF or bad input.
Example 1:
1 | int main() { |
Example 2:
1 | int main() { |
cin converts to:
trueif all goodfalseif the stream has had a read failure>>means right bit shift operator in C/C++- a, b are int, a
>>b a’s bits to the right for b spots.- 21 = 10101
- 21 >> 3 = 10
101= 10 = 2
Question: How do the program knows whether >> is shifting bits or get from operator?
Answer: They depends on the provided arguments!
- when LHS is from
<iostream>(cin),>>is “get from” - when LHS is int,
>>is “shifting bits” - this is the very first example of function overloading:
- same function/operator has multiple, different implementations & meanings.
- the compiler choose wisely based on the provided number and type of the arguments, which are done at compile time.
- same function/operator has multiple, different implementations & meanings.
>>
cin >> i;
Let’s take a closer look at the >> operator:
- The
>>operator has 2 operands:cin, which is a streami, a variable to receive the input data.
- And it returns on result:
cin, the same stream used as the first operand- it also has a side effect
The fact that it returns a stream (cin), is why we can chain a series of these together
1 | cin >> x >> y >> z |
1 | // READ Example v3: |
1 | // READ Example v4: |
1 | // Read all ints from stdin, echo them to stdout until EOF |
Note:
clear()must come beforeignore(), calledignore()on a failed stream does nothing.ignore()removes 1 char from the stream.ignore(count)removes count chars from streamignore(count, '\n')removes count chars or everything up to and including the newline char, whatever comes first.
Formatted Output
1 | cout << 95 << endl; // Prints "95" |
hex: I/O manipulator - puts the stream into “hex mode” all subsequent integers are printed in hex.
1 | cout << dec; // switches the stream back to decimal mode. |
Example: print a dollar amount with leading asterisks in a width of 10 characters
1 | double m = 10.9; |
Note: Use import <iomanip>;
- Manipulators set flags in the stream. These are effectively global variables. Changes you make affect the program from that point on.
- Changes to the stream only lives to the end of the program. i.e. Once restart the program, stream is renewed.
C++ Features
String
C strings: An array of char (char * or char[]) terminated by a null char (\0)
- must explicitly manage memory - allocate more memory as strings get bigger
- easy to overwrite the \0 at the end.
- one of the biggest sources of security vulnerabilities
C++ strings: GOOD NEWS, built-in string data type.
- intuitive, easy-to-use
- string grow as needed (no need to manage memory explicitly)
- safer to manipulate.
1 | string s1 = "Hello"; |
Note: C++ Strings are created from C string on initialization.
String operations:
- equality/inequality: ==, !=
s1 == s2|s1 != s2 - comparisons:
<,<=,>, etc. (lexicographic by default) - length:
s.length(). → O(1) time. “String structure stores each string’s length” - concat:
s3 = s1 + s2;s3 += s1;← s3 need to be pre-defined.
1 | string s1 = "Hello"; |
- individual chars:
s[0]- returns first chars[1]- returns second char
- mutable
s[0] = 'h';
Example: Read Strings
1 | string s; |
What if we want the whitespace?
1 | string s; |
Streams are an abstraction. “They wrap an interface of “getting & putting items” around the keyboard & screen.“
Are there other kinds of “things“ that could support the “getting and putting“ interface?
File Stream/1
- read and write a file instead of stdin/stdout.
std::ifstream- a file stream for readingstd::ofstream- a file stream for writing- must import
<fstream>;
File access in C:
1 |
|
File access in C++:
1 | import <iostream>; |
Note:
- Anything you can do with
cin/cout, you can do with anifstream/ofstream.
String/2
import <string>;- Extract data from chars in a string:
std::istringstream. - Send data to a string as chars:
std::ostringstream.
1 | import <sstream>; |
1 | // E.g. -> convert string to number |
Compare the two implementations:
1 | // Earlier Version |
1 | // E.g. -> Echo all numbers, skip all non-numbers |
Command Line Arguments
To accept command line arguments in C or C++, always give main the following parameters:
int main(int argc, char *argv[]) {...} where:
int argcstands for # of CMD Line Argsargc>= 1, where first value is the program name itself.
char *argv[]is an array of C-style stringsargv[0]= program nameargv[1]= first argargv[2]= second arg- …
argv[argc]= NULL TERMINATOR
1 | // Example: ./myprog abc 123 |
Default Function Parameters
1 | void printFile(string name = "file.txt") { |
Note about behavior:
- optional parameters must be last
int f(int n = 2, int y = 3, int z = 4) { }f(0)→f(0, 3, 4)f(1, 2)→f(1, 2, 4)f()→f(2, 3, 4)
Also note: the missing parameter is supplied by the caller, not the function.
WHY:
The caller passes params by pushing them onto the stack.
The function fetches params by reading them from the stack from where they are expected to be.
- If an argument is missing, the function has no ways of knowing that.
- It would interpret whatever is in that part of the stack as the
arg.
So instead, the caller must supply the extra param if it is missing.
Therefore, when writing
printFile();The compiler replaces this with
printFile("file.txt");- Compiler do the duty for us, Function is duty-less.
printFile();→printFile("file.txt");→ stack framewrite code compile run time
For this reason, default arguments are part of a function’s interface, rather than its implementation.
If you are doing separate compile, defaults go in the interface file, not the implementation file.
Overloading
In C:
1 | int negInt(int n) {return -n;} |
In C++;
1 | int neg(int n) {return -n;} |
The idea of having same function name for different implementations is called OVERLOADING.
Simplifies the code because reusing function with different # and types of parameters inside parameter lists is legit.
The compiler chooses the correct version of
neg(), for each function call, at compile-time.- Based on the # or types of the
argsin the function call.
- Based on the # or types of the
Hence, OVERLOAD must differ in # or types of arguments
- Just differing return type is not enough.
- Example (Already seen):
<<,>>,+- Their behavior depends on types of arguments.
- Example (Already seen):
Structs
In C++;
1 | struct Node { |
1 | struct Node { |
Constants
1 | const int passingGrade = 50; // Must be initialized |
- Declare as many things
constas you can, it help catches errors.
Constant Node
1 | Node n {5, nullptr}; // Syntax for null ptrs in C++ |
Interesting notes:
1 | void f(int n); // Taking int |
Use the null pointer to indicate nullity.
1 | const Node n2 = n; // Immutable copy of n |
Parameter Passing
Recall:
1 | // Pass a value |
Q: Why cin>>x and not cin >> &x?
A: C++ has another pointer-like type - references
References - Important
1 | int y = 10; |
References are like const pointers with automatic dereferencing.
1 | z = 12 (Not *z = 12) // now y == 12 |
1 | int *p = &z; |
In all cases, z behaves exactly like y. z is an alias (another name) for y.
Question: How can we tell when & means “reference” vs. “address of”
[^]: Overloading, but how??
Answer: Whenever & occurs as part of type (e.g. int &z), it always means references. When & occurs in an expression (e.g. inc(&z)), it means address of (or bitwise-and).
Things you can’t do with lvalue references
- Leave them uninitialized e.g.
int &z- Illegal- must be initialized with something that has an address (an lvalue), since refs and ptrs.
- x = y
- y = right value (interested in actual value)
- x = left value (interested in its location)
- Has to denote a location (Has an address)
- x = y
int &x = 3;is illegal- 3 doesn’t has an address
int &x = y+z;is illegal- y + z doesn’t has an address
int &x = y; legal- y has an address (lvalue)
- must be initialized with something that has an address (an lvalue), since refs and ptrs.
- create a pointer to a reference
int &* p;illegal- a pointer to a reference to an int
int *& p;legal- a reference to a pointer to an int
- create a reference to a reference
int && r = ...illegal- perhaps simply use a reference directly to the value
- will compile!
- && means something different (later)
- create an array of references
int &r[] = {_, _, _};illegal
Things that you can do
- Pass as function parameters
void inc(int &n) {++n;} // No pointer deref- const ptr to the arg (x), changes will affect x
int x = 5; inc(x); count << x; // 6
Then why does cin >> x work? Takes x as a reference
1 | istream &operator >> (istream &in, int &x); |
Question: Why is the stream being taken & returned as a ref? And what does returning by ref mean?
Answer: Need a better understanding of the cost of parameter passing.
Pass-by-value, e.g. int f(int n) {...} copies the arguments.
- if the arguments are big, copy is expensive
1 | // Example |
If applicable, Pick reference over pointers
- Const - Can’t change where reference points to
- References can never be null - no need to worry
What if a function does want to make changes to rb locally, but does not want these changes visible to the caller? (Being fast)
Then the function must make a local copy of rb:
1 | int k(const ReallyBig &rb) { |
But if you have to make a copy anyway, it’s better to just use pass-by-value and have the compiler make it for you - maybe it can optimize something.
Advice:
- Prefer pass-by-const-ref over pass-by-value for anything larger than a pointer, unless the function needs to make a copy anyway - then just use pass-by-value.
Also: int f(int &n); int g(const int &n);
f(5);illegal, can’t initialize an lvalue ref (n) to a literal value (non-lvalue)- if n changes, can’t change the literal 5.
g(5);legal, since n can never be changed ↑, the compiler allows this.- HOW? important - the 5 is stored in a temporary location (stack)
- so the ref has something to point to → towards somewhere in the stack
- example putting const makes function more applicable
- so the ref has something to point to → towards somewhere in the stack
- HOW? important - the 5 is stored in a temporary location (stack)
So, in the case of
1 | istream &operator >> (istream &in, int &x); |
the istream is passed and returned by reference to save copying.
IMPORTANT: because stream variable are not allowed to be copied.
Dynamic Memory
In C:
1 | int *p = malloc(# * sizeof(int)); |
In C++: new/delete - type-aware, less error-prone
- knew the memories, doesn’t have to manually allocate
1 | // Example |
1 | struct Node {...} |
All local variables and function parameters reside on the the stack
- they are deallocated automatically when they go out of the scope (stack is popped)
- if they are pointers, the memory they point to is not deallocated automatically (require manual delete).
newallocated memory resides on the heap- remains allocated until delete is called
- if don’t delete all allocated memory → Memory Leak.
- Calling delete on the same pointer more than once is an error.
- Program will crash: SEGV
- Calling delete on a
nullptris harmless - safe and acceptable. - Never call delete on a stack-allocated object → program will crash
Methods of returning values
Return by value:
1 | // Okay |
Return by pointer:
1 | // BAD |
Return by reference:
1 | // BAD |
1 | // Recall example in operator >> |
Return by Pointer (Fixed):
1 | Node *getmeANode() { |
Why is it okay to return a reference here?
1
istream &operator>>(istream &in, int &n)
- main:
cin >> n - the argument istream &in was already available to the caller of operator >> so returning a reference back to it is okay
- cin and n are in main so when you return the istream, you are returning it in main, not out of scope when istream is finished
- main:
Operator Overloading
Recall from earlier how the <<and >> operators were overloaded to be used for input/output, We can actually overload any operator to have customized behavior for certain input types. Most notably, this includes user-defined types (structs and classes).
1 | <return_type> operator<op>(...<input (s)>...) { |
Let’s consider a custom structure
1 | struct Vec { |
Example: Overloading >> and << operators
1 | cout << v1 << endl; |
Modules
When programming, we can split our programs into multiple modules, where each module provides both: an interface and an implementation.
- Interface (
.h): Declaration, Type definitions and prototypes for functions. - Implementation (
.cc): Full definitions for every provided function.
Interface File (Vec.cc): New syntax for C++20 and is NOT backward-compatible with #include.
1 | // Example Interface (Vec.cc) |
Implementation File (Vec-impl.cc)
1 | // Implementations |
Client Code (main.cc)
1 | // Client |
Note:
- Interface file starts with export module (______);
- Implementation files starts with module (______);
- Client files use import (______);
- These lines must be the first line
Separate Compilation
Speed up compilation by only compiling what’s necessary.
Files are compiled in dependency order:
- Interface files first
- Implementation / Client code second
Separate Compilation in dependency order:
-c: Produces an Object file (.o); Only compiling the file without linking, neither create an executable.
1 | g++20 -c Vec.cc // Creates Vec.o |
The command to link all the object files and produces an executable is:
1 | g++20 Vec.o Vec-impl.o main.o -o main |
1 | g++20 Vec-impl.o main.o -o main // Omitting Vec.o is Valid, compiler knows which interface file is corresponding from gcm.cache. |
Now the executable file can be run as
1 | ./main |
We must compile interface files in C++ unlike in C where we only include header files (.h) inside the implementation files.
We must always compile system libraries/modules before compiling any user-defined modules.
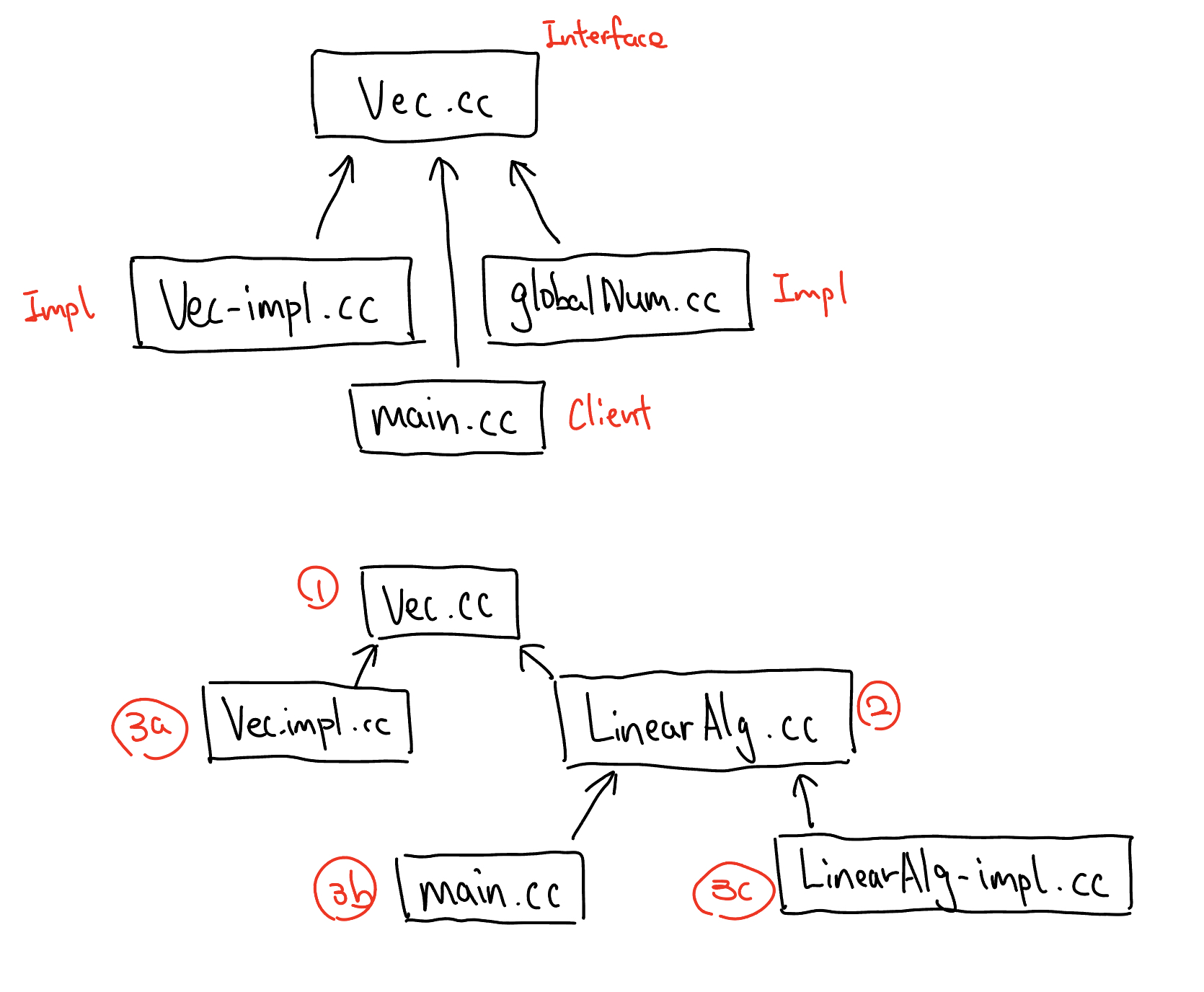
A -> B means A depends on B. If we were compiling, we would need to compile B first.
Classes
Classes are the main difference between C and C++.
Simply speaking, a class is a struct with functions in it.
Example:
1 | // Student.cc |
Implementation of a class function can be either in interface file (inside the struct) or in implementation file. Writing in implementation file is recommended.
Student is a class. The functions in it gives the struct behavior.
s is an object - a particular instance of a class.
assignments midterm and final are called data members, or member fields or (fields), or member variables.
:: - “scope resolution operator”. Locate the context. Define a function inside a class, also provide namespace.
Student::grade is a “member function” or “method”. (Meaning grade in the context of class Student)
The fields: assignments, midterm, and final are fields of the receiver object - the object upon which the grade method was called.
1 | s1.grade(); // method call | uses s1's data members. |
Question: What do assignments, midterm, final mean inside of Student::grade?
- They are fields of the receiver object - the object upon which graded was called.
- How do we know which data in the structure’s field corresponds to which receiver object?
Formally, every method has a hidden extra parameter called this, which is a pointer (not a reference) to the receiver object. (It is a pointer to the object that the method was called on)
1 | // We write |
Inside the function, <var> and this-><var> is the same thing, so they can be used interchangeably, when <var> is any fields inside the class/struct.
Big Five
These are methods you may have to implement in your classes.
- Constructors (
ctor) - Copy Constructors (
cctor, copyctor) - Destructors (
dtor) - Copy assignment operators
- move constructors
- move assignment operator
Constructors (Initializing Objects)
1 | Student s1 {60, 70, 80} // Ok but limited |
To control how objects are created, write a constructor (ctor). Constructors have no return type and have the same name as the class/struct.
1 | // Student.cc |
When there is a constructor, program passes the arguments to the constructor. When there is not, then this is C-style field-by-field initialization. C-style struct initialization is only available if you have not written a constructor.
The major benefits of constructors is that they are functions and can thus be customized as such:
- Argument bounds checking
- Default parameters
- Overloading
- Sanity checks
Any constructor that can be called with 0 arguments is a “default constructor”. This can be either the constructor has no arguments or because it has default parameters. If we do not write any constructors, then the compiler provides the default constructor.
Compiler-provided default constructor:
- Primitive fields(
bool,int,char`, pointers) - left uninitialized - Object fields(
class,struct) - calls the object’s default constructor
Example: Class with default constructor
1 | struct Student [ |
Whenever an object is created, a constructor is always called.
If we do not have a default constructor for a class, that can cause issues with any classes containing classes without default constructor. Remember this is only an issue when we provide our own custom constructor as compiler provides a default constructor by default.
1 | struct Vec { |
1 | struct Basis { |
The built-in default ctor for Basis would attempt to default-construct all fields that are objects: v1 and v2 are objects. Since they have no default ctor, Basis cannot have a built-in default ctor.
Providing a default constructor might seem to work but it actually does not solve the issue.
1 | struct Basis { |
NOTE: Whenever we have a usable object in C++, it has been constructed at some point.
The body of the ctor can contain arbitrary code, so the fields of the class are expected to be constructed & ready to use before the ctor body runs.
Steps for object creation:
- Enough space is allocated
- Fields are constructed in declaration order (i.e.
ctorrun for fields that are objects) ctorbody runs
Initialization of v1, v2 must happen in step 2, not step 3. How to accomplish that?
We can fix this issue with a Member Initialization List (MIL). The MIL provides default values to initialize the fields with in step 2 instead of using the default constructor.
1 | Student::Student(int assns, int mt, int final): |
NOTE: We can initialize any field this way, not just object fields.
1 | // For Basis |
More generally:
1 | struc Basis{ |
NOTE: The MIL is ONLY provided in the interface file.
For something like the Basis class, we generally want 2 different constructors:
- Default Constructor
- Custom Constructor (user provides all fields)
1 | // Option 1: Providing default values in the default constructor |
If there’s no MIL provided, then the default values provided during declaration are used. Fields are initialized based on the order in which they were declared in the class, even if the MIL order them differently. The order of the fields in the MIL doesn’t matter.
Using the MIL is sometimes more efficient than setting fields in the ctor body. Since for the constructor body, each object needs to be default constructed first before it’s overwritten is reset to the provided value. This causes extra memory write cycles. Hence it is recommended to use MIL whenever possible.
Consider:
1 | struct Student { |
Versus MIL:
1 | struct Stuent { |
An MIL must be used for any fields that satisfy any of these conditions:
- objects with no default constructor
- const or references
Copy Constructors
Consider:
1 | struct Student { |
Examples shown above invoke the copy constructor that we get for free. It creates an object from another of the same type. By default, the compiler-provided constructor copies each field from the original object into the object being constructed.
Note: Every class comes with
- Constructors (default-constructs all fields that are objects)
- lost if you write any custom constructor
- Destructors (frees up memory when the object is created)
- Copy Constructors (just copies all fields)
- Copy assignment operators
- move constructors
- move assignment operator
Example: Copy constructor for Student class
1 | struct Student{ |
It is important to note that adding ANY constructor (including a copy or more constructor) will remove the compiler-provided default constructor.
Example: When we cannot use the compiler provided copy constructor
1 | struct Node { |
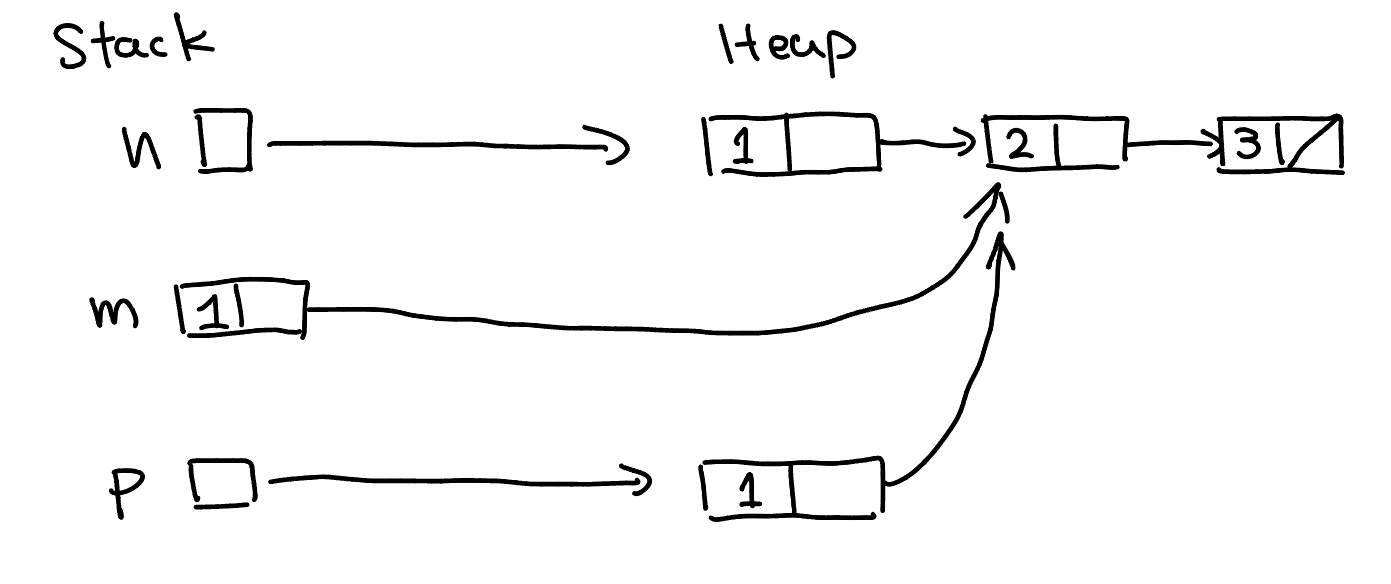
In this case, only the first node is actually copied. This is an example of shallow copy, where only first layer is copied over. Instead we want a deep copy, where we will end up with 3 identical but still independent lists.
In order to do that, we must write our own copy ctor.
1 | struct Node { |
The above example will perform a recursive deep copy, and when called on a linked list, will produce another that is identical but completely separate.
The copy constructor is called in the following situation:
- Constructing (initialized) one object from another of the same type
- Object is passed by value
- Object is returned by value
The truth is more nuanced, as we will see.
Explicit / Implicit Constructors
1 | // Example |
Single argument constructors allow implicit conversions. For example with the Node class shown above, we can construct it by just providing a single integer. Thus, the following behavior make sense:
1 | Node n{4}; |
We have experienced this with C++ string initialization:
1 | string s = "Hello"; |
This is allowed because there is a single argument constructor for std::string that tales in a const char*.
However, implicit conversions also allow for some unintuitive behavior:
1 | void f(Node n) { |
In the example shown above, the constructor for Node is called, which takes in an int. Once a Node is constructed, it is passed to f.
Implicit conversions can be dangerous:
- Accidentally passing an int to a function expecting a Node
- silen conversion
- compiler does not signal an error
- potential errors not caught
In order to not letting you compiler helping you, disable the implicit conversion by prefixing the constructor with the explicit keyword:
1 | struct Node{ |
Destructors
- Called when a stack-allocated object is popped off the stack, or when
deleteis called on heap allocated memory. - A special method that runs when an object is destroyed.
The default compiler-provided destructor calls the destructor on all constituent objects, and does nothing to non-objects.
Steps of C++ object destruction:
- Destructor body runs
- Field’s destructors are invoked (destructor runs for all object fields) [In reverse declaration order]
- space is deallocated
Reasons for writing custom destructors:
Similar to with constructors, custom classes for data structures, especially those that references themselves will need a custom constructor. Let’s see why using the Node class as an example:
1 | struct Node { |
Here, next is a Node * or Node pointer. Thus it is not an object and no destructor will run for it. When we call delete on a node in a linked list, only that node will be deleted, and all the subsequent nodes will remain in memory but inaccessible, causing a memory leak.
Example: Node class with destructor.
1 | struct Node { |
NOTE: The base case running delete nullptr; is guaranteed safe and does nothing more. Hence the recursion stops.
Copy Assignment Operator
1 | Student s1{60, 70, 80}; |
Copy assignment operator runs when we assign a value to another of the same type (that already exist). The compiler-supplied default version assigns each field of the object.
Similar to constructors and destructors, this may not work for many custom classes, especially those that have recursive pointers and/or are needed for data storage.
Example: Copy Assignment Operator for Node class (Version 1 - Dangerous):
1 | struct Node { |
The above code works for almost all cases, but it’ll cause a runtime error when assigning a node to itself (n = n), known as self assignment.
1 | Noded n{1, new Node {2, new Node {3, nullptr}}}; |
When writing operator=, ALWAYS make sure it works well in the case of self-assignment:
Example: Copy Assignment Operator for Node class (Version 2 - Better)
1 | struct Node { |
Question: How big of a deal is self-assignment? How likely am I to write n = n?
Answer: Not that likely, but considering *p = *q if p & q point to the same location. Or a[i] = a[j] if i & j happen to be equal (say in a loop). Because of aliasing, it is a big deal.
This version is better, but we can make a better implementation. Remember new could fail for not having enough space to allocate. Since when new fails, it aborts immediately instead of returning a nullptr. This causes next to be deleted but not reassigned, and then next will points to freed memories.
Example: Copy Assignment Operator for Node class (Version 3 - Final)
1 | Node &Node::operator= (const Node &other) { |
Alternate: copy-and-swap idiom.
Copy/Swap Idiom
There’s another method to implement copy assignment.
A function called std::swap in <utility> library. Running swap(a, b); will swap the values of a and b.
1 | import <utility>; |
Move Constructors
R-values & R-value references
Recall:
- an lvalue is anything with an address
- an lvalue reference(&) is like a
const ptrwith auto-dereference - always initialized to an lvalue. - they don’t bind with temporary values
1 | Node oddsOrEvens() { |
- Compiler creates a temporary object to hold the result of
oddsOrEvens() - other is a reference to this temporary
- copy constructor deep-copies the data from this temporary
BUT - the temporary is just going to be discarded anyways, as soon as the struct Node n = oddsOrEvens(), is done.
- Wasteful to have to copy the data from the temp.
- Why not just steal it instead? - Save the cost of copying
We need to be able to tell whether other is a reference to a temporary object (where stealing would work), or a standalone object (perform a deep copy).
Node && - rvalue reference. Can bind to temporary values. It is a reference to a temporary object (rvalue) of type Node.
Example: Move constructors for the Node class:
1 | struct Node { |
Nothing was copied/changed here except for the ownership of the data.
Move Assignment Operator
This is similar to the move constructor, except that it is used when reassigning the value of a variable that has already been initialized.
1 | Node m; |
1 | struct Node{ |
If other is a temporary (rvalue), the move constructor or move assignment oerator is called instead of copying resources. If you only write the copy constructor / assignment operator, only these will be used.
Copy/Move Elision
1 | Vec makeAVec() { |
Answer: This only uses basic constructor. There is no copy constructor nor move constructor. In certain cases, the compiler is required to skip calling copy/move constructors.
Compiler writes the value directly to main itself and stores it inside the space occupied by v, instead of making a Vec in makeAVec() and moving it to main. This is called Copy/Move Elision.
1 | // E.g |
This happens even if dropping constructor calls would change the behavior of the program (e.g. if constructors print anything).
We are not expected to know exactly when elision happens, just that it is possible to happen.
Summary: Rule of 5 (Big 5)
If you need to write any one of the Big 5 (destructor, copy constructor, copy assignment operator, move constructor, move assignment operator): then you should probably write them all out.
However, many classes wouldn’t need any of these, and try to avoid reinventing the wheels possible, and using the default implementations are fine.
Recall three important indicative understanding of CS246:
- References
- Stack & Heap
- Ownership
The Big 5 are usually necessary for classes that manages resources (i.e. memories, files).
Features of Objects
Member Operators
Notice: operator= is a member function of the class (method). Previous operators like operator+() have been standalone functions.
When an operator is declared as a member function, *this plays the role of the first (left) operand.
1 | struct Vec{ |
How do we implement k * v? This can’t be a member function (method) since the first argument is not Vec, thus it must be external (standalone) function.
1 | Vec operator*(const int k, const Vec &v) { |
Advice: If you overload arithmetic operators, overload the assignment versions of these as well, and implement the former in terms of the latter (reuse logic from arithmetic methods):
1 | Vec &operator += (Vec &v1, const Vec &v2) { |
Some operator overloads must be member functions (methods):
operator=operator[]operator->operator()operatorT(where T is a type)
Some must not:
I/O Operators:
1 | struct Vec { |
What is wrong? This makes Vec become the first operand, not the second. View it as v << cout, this is morally and semantically wrong, while compiler will actually allow this to happen.
So always define <<, >> as standalone functions.
Arrays of Objects
Let’s consider Vec object again:
1 | struct Vec{ |
The above lines of codes will lead to compilation errors. This is because when creating an object in C++, it need to be initialized. When making an array of Vecs, they all needs to be initialized. However there is no default constructor, which leads to an error.
Options:
Provide a default constructor to the object.
- Not a good idea (i.e. Student class / Empty name), unless it makes sense for the class to have a default constructor.
For stack arrays, provide value during initialization.
vec moreVecs[3] = {{0, 0}, {1, 1}, {2, 4}};- This method works, but the use cases is limited
For heap arrays, use an array of pointers to objects.
Vec **vp = new Vec*[5];vp[0] = new Vec{...};vp[1] = new Vec{...};…When we are done using this array, we’ll need to manually free all the memory, since they’re allocated in heap.
for (int i = 0; i < 15; i++) delete vp[i];delete[] vp;
Const Objects
1 | int f(const Node &n) {...} |
Constant objects arise often, especially as parameters.
Objects can be constant. A constant object is that its fields cannot be mutated after initialization:
1 | const student s{60, 70, 80}; |
However, we cannot run any of the object’s inbuilt functions:
1 | const student s{60, 70, 80}; |
Issue: The compiler does not know whether s.grade() will modify any of the object’s fields or not. The function call is prevented by compiler because if s.grade() will respect the constness of s.
If it is certain grade() won’t modify any of the fields, we must declare its behavior to use grade with a const object.
Example: Functions that work with const objects:
1 | // Interface |
Note: The const suffix must appear in both interface and implementation files. Only const methods can be called on const objects. Compiler checks that const methods do not actually modify any fields.
With the above code, we can run the grade() on a const object:
1 | const student s{60, 70, 80}; |
const objects may only have const methods called on them. Non-const objects may have either const or non-const methods called on them.
Now what if we want to collect usage statistics on Student objects?
1 | struct Student{ |
This would not work because the function increments calls.
Issue: Difference between physical vs logical constness:
- Physical: Whether or not the actual bits that make up the object have changed.
- Logical: Whether or not the updated objects should logically be regarded as different after the update.
We can make an exception to what the compiler checks be declaring a field to be mutable.
1 | struct Student{ |
Static fields and methods
What if I want to record the number of calls for ALL Student objects, and not just one. Or keep track of number of Students created?
We use static fields (associated with the class itself, not any specific instance (object)):
1 | struct Student { |
Any static fields are defined for the object rather than for each instance, and the value is shared across all instances of the object. The inline keyword is used to allow static fields to be initialized directly in the interface rather than in the implementation file.
Static methods, just like static fields, are defined for the class rather than for any one particular object. Static methods can only access static fields. No need for this. Don’t depend on the specific instance.
1 | struct Student { |
In order to call this function we call Student::howMany();, calling s.howMany() won’t work.
Three-Way Comparison
Let’s go back to C and see how string comparison works: strcmp(s1, s2):
Return:
- negative if
s1 < s2 - zero if
s1 == s2 - positive if
s1 > s2
In order to compare 2 strings, we would do the following:
1 | // IN C |
1 | // IN C++ |
C++ version is easier to read. However, notice that in C, there’s only one string comparison (running strcmp once). In C++, there are 2 string comparisons being done. This causes an unnecessary waste of resources.
As of C+=20, there’s a efficient way:
1 | // 3-way comparison operator: (Spaceship operator) |
Using the 3-way comparison operator is identical to using strcmp in C. Note that in order to use it we need to import the <compare> library.
1 | import <compare>; |
std::strong_ordering is a lot to type. Instead, we can use automatic type deduction:
1 | auto n = (s1 <=> s2); |
We may also overload the spaceship operator for our own data types. If we define <=> for a type, we also automatically get all the other comparison operators automatically:
- v1 == v2
- v1 != v2
- v1 <= v2
- v1 >= v2
- v1 < v2
- v1 > v2
Even after we define the spaceship operator, we can overload operator== again, since it’s sometimes possible to check equality much more efficiently than comparison.
Example: Operator overloading the spaceship operator:
1 | struct Vec { |
Here, we are simply comparing the fields in declaration order. If that is the case, we can use the default version of operator<=>. This is not provided by default and we need to specify that we are using default behavior.
1 | struct Vec { |
Node: = default also works for all constructors, destructors, and operators that the compiler provides by default.
Consider a case where = default is not appropriate for <=>.
Example: Linked lists
1 | struct Node { |
Encapsulation
Consider our linked list example again:
1 | struct Node { |
When this program finished running, the following happens:
- n1 -
dtorruns, entire list that are on heap is deleted. - n3 -
dtortries to delete n2, but fails because it tries to freen2,which is stack allocated.
Even if we did these with variables that were all heap-allocated, we would end up with double-free errors on n1.
Class node relies on an assumption for its proper operation: that next is either nullptr or was allocated by new.
These are invariants - properties of a data structure that must hold true - upon which Node relies.
But we, can’t guarantee this invariant - can’t trust user to use Node properly. Because users can easily violate these invariants.
- But not if the client can rearrange the underlying data.
Encapsulation provides a solution to users violating invariants.
Users should treat our objects as “capsules” or “black boxes”, where users have no access to the underlying data, but rather interact with the objects by calling methods.
This is where access specifiers are useful. There are 2 different types:
publicfields / methods: can be accessed everywhere.privatefields / methods: can be accessed / called within class methods.
Example: Vec struct using access specifiers
1 | struct Vec{ |
It is preferred to keep fields private by default, only method should be public.
Class has default visibility of fields / methods private, Struct has default visibility of fields / methods public.
Note that this is the only difference between class and struct.
Example: Vec object implemented as a class
1 | class vec { |
Example: Revisit our linked list - add encapsulation, protect invariants:
1 | // List.cc |
Only List can create / manipulate Node objects.
Thus we can guarantee the invariant that next is always either nullptr or allocated by new.
Encapsulation gives us a lot of benefits, but let’s talk about something not so good.
Issue: Printing a list take O(n^2) time. List::ith() cost O(i) time, calling List::ith() repetitively will eventually ends up with O(n^2) time.
How can we have faster iteration while maintaining encapsulation?
Iterator Pattern
We can’t traverse the list from node to node as would in a linked list. We can’t expose the nodes, or we lose encapsulation.
SE Topic: Design Patterns
- Certain programming challenges arise often
- Keep track of good solutions to these problems - reuse & adapt them
Iterator Pattern:
By creating an iterator class, which is an abstraction of a pointer. We keep track of how far we have reached, and allow the user to access data but not modify anything.
Recall from CS136:
1 | for (int *p = arr; p != arr+size; ++p) { |
Example: List data structure with Iterator pattern.
1 | class List { |
1 | int main() { |
If you have a class with the following:
beginandendmethods returning some iterator type.- This iterator type has prefix
++,!=, and unary*.
You can use a range-based for loop.
Example: Range-based for loop with iterator class
1 | // If you want to get a copy of the data stored in the class |
If you want to mutate list items (or save copying):
1 | for (auto &n : l) { |
Encapsulation continued
List client can create iterators directly:
1 | auto it = List::Iterator {nullptr}; |
- This violates the idea that all iterators are created by calling
begin()orend(). WhileList::Iterator{nullptr}is the same thing that is returned byend()in this case, it’s not necessarily the case with other data structures.
Consider making List::Iterator‘s constructor private:
- Being a
privatemethod, it can not be called by the user. - However, even
Listwould not be able to make iterators inbegin()orend().
Solution: Make an exception for the List class so that it gets privileged access to the normally private constructor for Iterator.
- Make it a friend
1 | class List { |
If class A declares class B as a friend, then B can access all the private fields / methods of A.
Now, a user can now create an Iterator, also also List, we can be sure that all Iterators can be created via begin() or end().
Advice: Limit your friendships - More friendships means more difficulty to reason about private fields / methods.
Instead of friendships, consider using accessor / mutator methods instead (getters / setters).
Example: Accessors and mutators for the vec class.
1 | class Vec { |
What if we want to use operator<<, this needs both x and y, but must be a standalone function.
We declare friend methods just like how we declare friend classes. Instead of providing a class name, we provide a function signature.
Example: Declaring output operator as a friend function.
1 | ostream& operator<<(ostream& out, const vec& v) { |
Equality Revisited
We now have an encapsulated List class.
We already have ith and addToFront methods. We could also add a length method.
Options:
- Loop through the nodes to count them:
O(n). - Store the length as a field of
List& keep it up to date wheneveraddToFrontis called:O(1).
Option 2 is preferred, as it optimizes equality.
Most lists will have different lengths, and so we could optimize the == operator by checking the length first, and only compare the individual values if the lengths differ. If lengths differ, then equality is calculated in O(1)1 time.
Example: Optimized equality operator for a List class.
1 | class List { |
Spaceship operator provides >=, <=, >, <, for List. We have overloaded the == operator, for which the compiler will use the custom optimized version, as well as for !=, which is just the negation of ==.
But in the special case of equality checking, we are missing out on a shortcut: Lists whose lengths are different cannot be equal. In this case, could answer “not equal” in O(1) time.
System Modelling
Visualize the structure of the system (abstractions + relationships among them) to aid design of implementations.
We want to graphically display the classes of a program at a high level.
We uses the popular standard language UML (Unified Modelling Language).
Example: UML Diagram for the Vec class.

Here, there are 2 different sections. Upper section is for variables and the bottom section is for functions. Anything prepended by a + is public, anything prepended by - is private.
Relationships Between Classes
Composition
Composition is one possible relationship between classes, where one classes is embedded within the other.
Example: Composition relationship.
1 | class Basis { |
Embedding one object (e.g. Vec) inside another (e.g. Basis) called composition.
Here, Basis is composed of 2 Vecs. They are part of a basis and that is their only purpose. This is also called “owns-a”. Here, Basis owns 2 Vecs.
Following is the UML diagram for the Basis example:
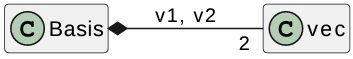
If “A owns-a B“, then:
Bhas no identity outsideA(No independent existence)- If
Adies,Balso dies. - If
Ais copied,Bis copied (deep copy).
An example would be: A car owns its engine - the engine is part of the car.
- Destroying the car will also destroys the engine.
- Copying the car will also copies the engine.
Implementation - Usually as composition of classes.
A <>—-> B means A owns some number of B’s.
- Can annotate with multiplicities, field names.
Aggregation
Aggregation is similar to Composition, except with some minor differences. Instead of one class being embedded in another, it’s rather linked to the other.
E.g.: Compare car parts in a car (“owns-a”) vs. car parts in a catalogue.
- The catalogue contains the parts, but the parts have an independent existence.
An aggregation relationship is also called “has-a”.
If “A has-a B“, then:
- If
Adies, thenBkeeps living. - If
Ais copied, thenBis not copied (shallow copy). Bmay have independent existence outside ofA.
Example: Aggregation relationship - Parts in a catalogue, ducks in a pond.
1 | class Student { |
The following is the UML diagram for the Student example:
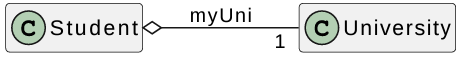
Case Study: Does a pointer field always mean non-ownership?
A node owns the node that follows it. (Recall that implementation of the Big 5 is a good sign of ownership)
The List owns the first node, but the ownerships are implemented via pointers.
Another view of lists & nodes.
We could view the List object as owning all the nodes within it.
What might this suggest about the implementation of Lists & Nodes in this case?
Likely, that List is taking responsibility for copying and construction/deconstruction of Nodes, rather than Node.
Possible iterative (i.e. loop-based) management of pointers instead of recursive operations within Node.
Specialization / Inheritance
Suppose we want to track our collection of books.
1 | class Book { |
This is OK, but it doesn’t capture the relationships among Book, Text, and Comic.
And how do we create an array (or list) that contains a mix of these?
Could:
- Use a Union
1 | Union BookTypes { Book *b, Text *t, Comic *c}; // Stores ONE of the data types |
- Array of
void*- Pointer to anything
Not good solutions - subvert the type system.
Rather, observe: Texts and Comics are kinds of Books - Books with extra features.
To model in C++, we introduce inheritance.
1 | class Book { // Base class or Superclass |
Derived classes inherit fields and methods from the base class. So Text, Comic get title, author, length fields. Any method that can be collection on Book can be called on Text, Comic.
Who can see these members?
title, author, length - private in Book - outsiders can’t see them.
Can Text, Comic see them? NO, even subclasses can’t see them!
How do we initialize Text? Need title, author, length, topic
Example: Incorrect constructor for a subclass.
1 | // Warning: This code doesn't work and the reason why is explained below |
Wrong for 2 reasons:
- title, etc. are not accessible in Text (even if they were, MIL only lets you mention your own fields)
- Once again, when an object is created:
- Space is allocated
- Superclass constructor runs NEW
- Fields are initialized via MIL
- Constructor body runs
So a constructor for Book must run before the fields of Text can be initialized. If Book has no default constructor, a constructor for Book must be invoked explicitly:
1 | class Text: public Book { |
Good reasons to keep superclass fields inaccessible to subclasses.
Protected Variables and Methods
If you want to give subclasses access to certain members, use protected access.
Example: Different abilities for different subclasses.
1 | class Book { |
Not a good idea to give subclasses unlimited access to fields. Better - make fields private, but provide protected accessors / mutators.
Example: Protected mutators.
1 | class Book { |
Relationship among Text, Comic, Book is called “is-a”
- A text “is-a” Book
- A Comic “is-a” Book
![UML Fig 6] (https://raw.githubusercontent.com/M4cr0Chen/MyPic/refs/heads/main/img/202410241543154.png)
Virtual Methodss
Now consider the method isHeavy - when is a Book heavy?
- for ordinary books - a book is heavy if it’s more than 200 pages
- for texts - more than 500 pages
- for comics - more than 30 pages
1 | class Book { |
Now, since public inheritance defines an “is-a” relationship, we can do this:
1 | Book b = Comic {"A big comic ", _____, 40, _____}; |
Question: Is b heavy? i.e. b.isHeavy() - true or false? i.e. which isHeavy() runs? Book::isHeavy() or Comic::isHeavy()?
Answer: b is NOT heavy. Which means Book::isHeavy() runs.
Why? Book b is on stack, = Comic { ... }; is on heap
Explanation: We tries to fit a Comic object, where there is only space for a Book object. What happens? Comic is sliced. The hero field gets chopped off. Comic is coerced into a Book. So Book b = Comic { ... }; creates a Book and Book::isHeavy runs.
NOTE: Slicing takes place even if the two object types were of the same size. Having isHeavy() depend on whether Book & Comic are the same size would not be good.
When accessing objects through pointers, slicing is unnecessary and doesn’t happen.
1 | Comic c {___, ___, 40, ___}; |
Compiler uses the type of the pointer (or reference) to decide which isHeavy() to run - doesn’t consider the actual type of the object.
Behavior of the object depends on what type of pointer (or reference) you access it through.
How can we make Comic act like a Comic, even when pointed to by a Book pointer? I.e., how can you get Comic::isHeavy() to run?
Declare the method virtual.
1 | class Book { |
Virtual methods: Choose which class’s method to run based on the actual type of the object at run time. (Only applies if accessing through pointer/reference, otherwise slicing).
Example: my book collection
1 | Book *myBooks[20]; |
- Uses
Book::isHeavy()for Books - Uses
Comic::isHeavy()for Comics - Uses
Text::isHeavy()for Texts
Accommodating multiple types under one abstraction: Polymorphism (“many forms”).
Note: this is why a function void f(istream f) can be passed an ifstream, ifstream is a subclass of istream.
DANGER: What if we’ve written Book myBooks[20]; and try to use that polymorphically?
Consider
1 | void f (Book books[]) { |
What is c now?
1 | { |
Recommendation: Never use arrays of objects polymorphically. Use arrays of pointers.
Destructor Revisited
1 | class X { |
How can we make sure that deleting through a superclass pointer runs the subclass desctructor? - Declare the destructor virtual.
1 | class X { |
ALWAYS make the destructor virtual in classes that are meant to have subclasses, even if the destructor doesn’t do anything.
If a class is NOT meant to have subclasses - declare it final: classY find:public X {...};
Pure Virtual Methods
Consider 2 kinds of student: Regular and Coop.
1 | class Students{ |
What should we put for Student::fees()?
We’re not sure, since every student should be either Regular or Coop.
We can explicitly give Student::fees() no implementation.
1 | class Student{ |
A class with a pure virtual method cannot be instantiated.
1 | Student s; // Cannot do this |
This is called an abstract class, which purpose is to organize subclasses. Subclasses of an abstract class are also abstract unless they implement all pure virtual methods.
Non-abstract classes are called concrete.
1 | class Regular: public Student { |
UML:
- Virtual / Pure virtual methods: italics
- Abstract classes: italicize class name
Templates
Huge topic - just to highlight here.
1 | class List { |
What if you want a List of something else?
Whole new class?
OR a template - class parameterized by a type
Example: Implementing Stack using template
1 | template<typename T> class Stack { |
Example: Implementing List using template
1 | template<typename T> class List { |
Compiler specializes templates at the source code level, then compiles the specializations.
Standard Template Library (STL)
A collection of useful templated classes.
Dynamic length arrays: std::vector
Example: Client code of std::vector
1 | import <vector>; |
But also:
1 | std::vector w {4, 5, 6, 7}; // Note: no <int> |
- if the type argument of a template can be deduced from its initialization, you can leave it out!
is deduced here.
Example: Looping over vectors:
1 | // Regular loop (like array) |
More vector functions:
v.pop_back()remove last element
Use iterators to remove items from inside a vector.
Example: remove all 5’s from the vector v.
Attempt #1:
1 | for (auto it = v.begin(); it != v.end(); it++) { |
Why is this wrong? Consider: we can’t handle consecutive repetitive items.
Note: After the erase, it points at a different item.
The rule is: after an insertion or erase, all iterators pointing after the point of insertion / erase are considered invalid and must be refreshed.
Example: Code that iterates through a vector and removes all elements that are equal to 5
1 | for (auto it = v.begin(); it != v.end();) { |
Another thing to note:
v[i] is i-th element of v.
- This is unchecked, if you go out of bounds, that is undefined behavior.
v.at[i]
- Checked version of
v[i] - When goes out of bound
- Problem: Vector’s code can detect the error, but doesn’t know what to do about it.
- Client can response, but can’t detect the error.
- C solution: function’s return a status code or set the global variable error
- Leads to awkward programming
- encourages programmers to ignore error checks
C++ - when an error condition arises, the function raises an exception.
By default, execution stops, but we can write handlers to catch exceptions & deal with them.
Vector<T>::at throws an exception of type std::out_of_range when it fails, we can handle it as follows.
1 | import <stdexcept>; |
Now consider:
1 | void f() { throw out_of_range {"f"}; } |
In the above code, main calls h, h calls g, g calls f, f throws. The control goes back through the call chain (unwinds the stack) until the handler is found, all the way back to main, main handles the exception.
If there’s no matching handler in the entire call chain, the program terminates.
A handler can do part of the recovery job, i.e. execute some corrective code & throw another exception.
1 | // throw other exception |
maybe someError has a subclass: specialError
throw s: s may be a subtype of someError, and throws a new exception of type someError.
throw: actual type of s is retained.
A handler can act as a catch-all.
1 | try { ... } |
Note: You can throw anything you want, it doesn’t have to be an object!
Define your own classes (or use appropriate existing ones) for exceptions.
Example: Bad input
1 | class BadInput{}; |
Recap that in Assignment Operator:
When new fails: throws an exception std::bad_alloc.
NEVER: let a destructor throw or propagate an exception. If we let destructor throw exception:
- Program will abort immediately.
- If you want to let a destructor throw, you can tag it with
noexcept(false).
BUT: If a destructor is running during stack unwinding, while dealing with another exception, and it throws, you now have two active, unhandled exceptions, and the program will abort immediately.
Design Patterns (Continued)
In general, the guiding principle is to program to the interface instead of the implementation.
- The abstract base classes define the interface.
- work with base class pointers & call their methods.
- concrete subclasses can be swapped in & out.
- abstraction over a variety of behaviors.
Iterator Pattern
Example: Abstract Iterator Pattern
1 | class AbstractIterator { |
Then you can write code that operates over iterators:
1 | // Works over Lists and Sets |
Observer Pattern
Publish-subscribe model:
- One class: publisher / subject - generates data
- One or more subscriber / observer classes - receive data & react to it
Example: publisher = spreadsheet cells, observers = charts
- When cells change graphs update.
There can be many kinds of observer objects - the subject should not need to know all the details.
Here’s the UML diagram for the observer pattern: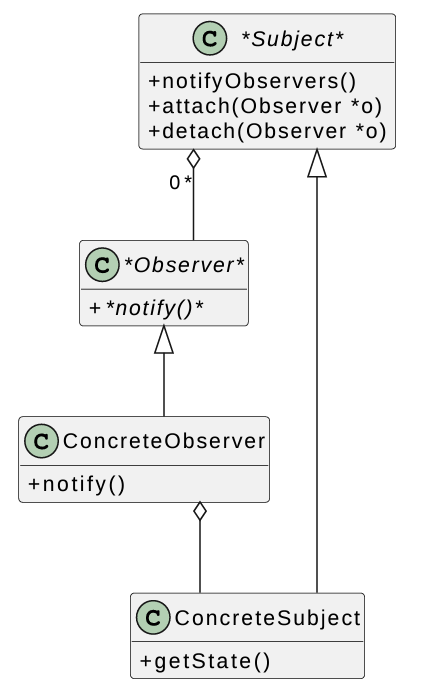
Steps of execution when the Subject is called:
- Subject’s state is updated
Subject::notifyObservers()is called - it calls every observer’s notify- Each observer calls
ConcreteSubject::getStateto query the state
Example: Horse races
Subject - Publishes winners
Observers - Individual betters - declare victory when their hose wins.
1 | class Subject { |
A4 & Final Project: Do the text version first, later add the GUI as an observer.
Decorator Pattern
We want to enhance an object at runtime -add functionality / features.
Let’s say we’re creating windowing system, we start with a basic window.
- Add a scrollbar when text exceeds the page length
- Add a menu
We want to choose these enhancements at runtime.
UML diagram for Decorator Pattern:
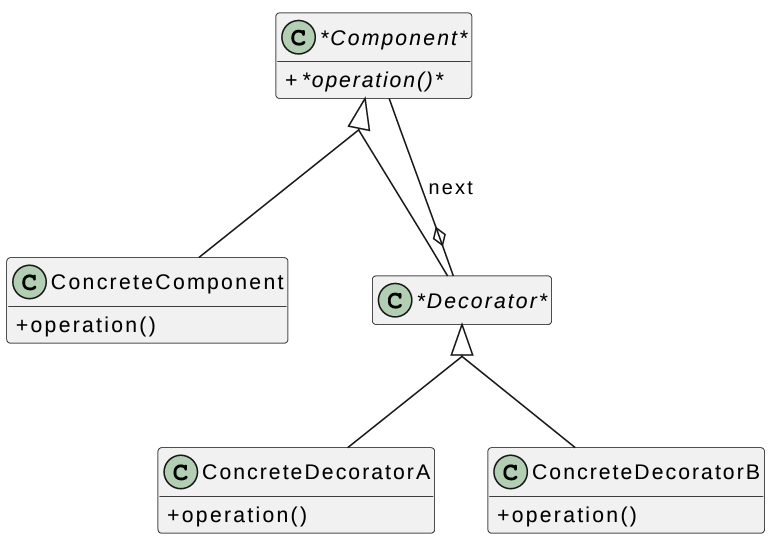
Components: defines the interface - operations your objects will provide
ConcreteComponent: implements the interface
Decorators: all inherit from Decorator, which inherits from component
- Every decorator is a Component AND every decorator has a component.
For example: A window with a scrollbar is a kind of window and has a pointer to the underlying plain window.
Window with a scrollbar & a menu is a window, which has a pointer to a window with a scrollbar, which has a pointer to a plain window.
Example: Pizza:
1 | class Pizza { |
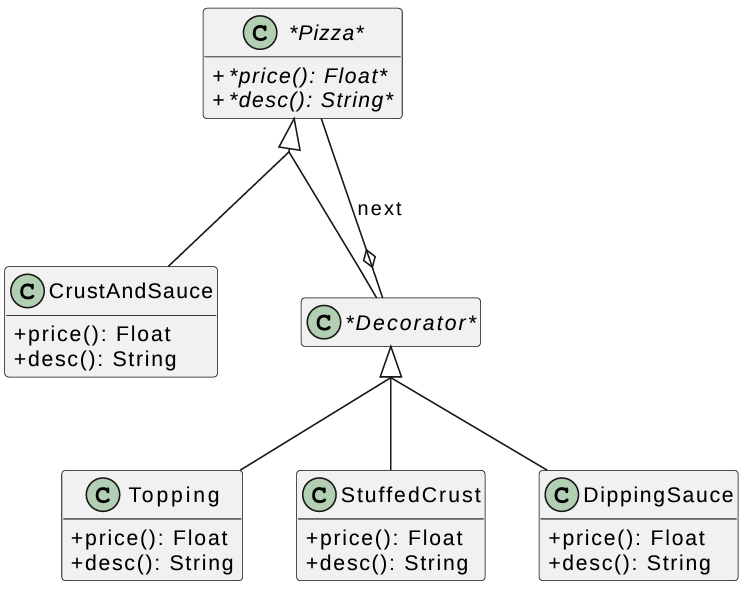
1 | class Decorator : public Pizza { |
Factoring Method Pattern
Write a video game with 2 kinds of enemies: turtles and bullets
- system randomly sends turtles & bullets, but bullets are more common in harder levels.
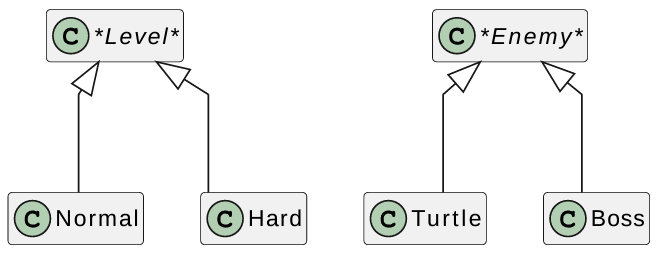
- Never know exactly which enemies comes next, so can’t call turtle/bullet constructor directly.
- Instead put a factory method (a method that makes things) in level that creates enemies.
1 | class Level { |
Template Method Pattern
- Want subclasses to override superclass behavior, but some aspects must stay the same.
Example: There are red turtles and green turtles.
Reviewing Big 5 with Inheritance
1 | class Book { |
- Calls Book’s copy constructor
- then goes field-by-field (i.e. default behavior) for the Text part
- same for other operations.
To write your own operations.
1 | // Copy Constructor |
Note: even though other “points” at an r-value, other itself is an l-value (so is other.topic).
std::move(x) forces an l-value x to be treated as an r-value, so that the “move” versions of operations run.
Operations given above are equivalent to default.
Now consider:
1 | Text t1 {...}, t2 {...}; |
This is a Partial Assignment, only the Book part is copied.
How can we fix this? We try making Book::operator= virtual.
1 | class Book { |
Note: different return types are fine, but parameters must be the same or it’s not an override (and won’t compile).
Hence, assignment from a Book object to a Text variable would be allowed:
1 | Text t = { ... }; |
If operator= is non-virtual, we get partial assignment through base class pointers. If it is virtual, it allows mixed assignment.
Recommendation: All super-classes should be abstract.
We rewrite the Book hierarchy:
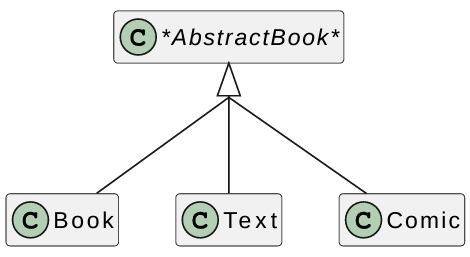
Example: Book with abstract superclass
1 | class AbstractBook { |
Note: pure virtual destructor must be implemented, even though it is pure virtual.
AbstractBook::~AbstractBook() {}
Advanced C++ Features
Coupling / Cohesion
Coupling: To what extent do modules depend on each other
- Low Coupling: Simple communications via parameters/result.
- High Coupling: Modules have access to each other’s implementation (
friends).
Cohesion: How much do parts of a module relate to each other?
- Low Cohesion: Module parts are unrelated (ex.
) - High Cohesion: Module parts co-operate to perform one task.
We desire low coupling and high cohesion.
Example: How to declare 2 classes that depends on each other
1 | class A { |
We can not determine the size of A or B. Thus, we break the chain of dependencies via a pointer.
1 | class B; // Forward declaration |
Q: How should A & B be placed into modules?
A: Modules must be compiled in dependency order, so we can’t forward-declare modules, or anything within another module. Hence A & B must reside in the same module. (Make sense since A & B are obviously tightly coupled).
Note: Forward declaration is not allowed for object fields or for inheritance.
Decoupling the Interface (MVC)
Your primary program classes should not be printing things.
Example: Let’s consider applying coupling and cohesion to Chess.
1 | class ChessBoard { |
This is a bad design, since it inhibits code reuse. Think about what if you want to reuse ChessBoard, but not have it communicate via std::out?
One solution: give the class stream objects, where it can send its input/output.
1 | class ChessBoard { |
This is better, but what if we don’t want to use streams at all?
Single Responsibility Principle: A class should have only one reason to change.
I.e. If two or more distinct parts of the problem specification affects the same class, the class is doing too much.
Each class should do only one job - game state & communication are two jobs.
Better: communicate with the ChessBoard via parameters & results.
- Confine user communication to outside the game class.
Q: So should main do all of the communication the call ChessBoard methods?
A: No, it is hard to reuse code if it’s in main.
So you should have a class to manage communication that is separate from the game state class.
Model View Controller (MVC)
Separate the distinct notions of the data (or state - “model”), the presentation of the data (“view”) and the control or manipulation of the data (“controller”).
Model:
- can have multiple views (e.g. text & graphics)
- doesn’t need to know about their details
- classic observer patterns (or could communicate via controller)
Controller:
- Mediates control flow between model & view
- may encapsulate turn-taking, or full game rules.
- may communicate with user for input (or this could be the view)
By decoupling presentation & control, MVC promotes reuse.
Exception Safety
Consider the following code, assuming C is any object
1 | void f() { |
What if g throws an exception? During stack-unwinding, all stack-allocated data is cleaned up: destructors runs, memory is reclaimed. Heap-allocated memory is never reclaimed.
Hence if g throws, c is not leaked, but *p is.
1 | void f() { |
This is ugly and error prone due to the duplication of code.
How can we guarantee that something (e.g. delete p) will happen no matter how we exit f? (normal or exception?)
In some language - “finally” clauses guarantee certain final actions - not in C++.
Only thing you can count on in C++ - destructors for stack-allocated objects will run. Use stack-allocated data with destructors as much as possible. Use the guarantee to your advantage.
RAII - Resource Acquisition is Initialization
Solution : Wrap dynamically allocated memory in a stack-allocated object.
Example from beginning of course:
1 | { |
the file is guaranteed to be released when f is popped from the stack (f’s destructor runs)
This can be done with dynamic memory
class std::unique_ptr
Constructor: Takes in a T*
Destructor: Deletes the pointer
Example: Using RAII in a function using unique_ptr.
1 | void f() { |
Whichever way f exits, the destructor will run on p, and the memory will be freed.
We could also use std::make_unique function also from memory
1 | void f() { |
Difficulty:
1 | unique_ptr<c> p {new C}; |
What happens when a unique_ptr is copied? We don’t want to delete the same pointer twice!
Instead - copying is disabled for unique_ptrs. They can only be moved.
Simple implementation:
1 | template <typename T> class unique_ptr { |
If you need to copy pointers, you need to first answer the question of ownership.
Who will own the resource? Who will have the responsibility for freeing it?
Whatever pointer that is, that should be our unique pointer. All other pointers should be raw pointers (you can fetch the underlying raw pointers with p.get()).
We now have a new understanding of pointers:
unique_ptr: indicates ownership - delete will happen automatically whenunique_ptrgoes out of scope.- raw pointer: indicates non-ownership, since a raw pointer is not considered to own the resources it points at, you should not delete it.
Moving a unique pointer = transfer of ownership
Pointers as parameters
1 | void f (unique_ptr<c> p); |
Pointers as results:
unique_ptr <c> f();- returns by value is always by move, so f is handing over ownership of the C object to the caller.C *g();- the pointer returned by g is understood not to be deleted by the caller, so it might represent a pointer to non-heap data or a pointer to heap data that someone else already owns.
Rarely, a situation may arise that requires true shared ownership, i.e. any of several pointers may need to free the resource.
- use std::shared_ptr
1 | { |
shared_ptrs maintain a reference count - count of all shared pointers pointing at the same object.
Memory is freed when the number of shared pointers to it will reach 0.
Consider:
1 | (define lst1 (cons 1 (cons 2 (cons 3 empty)))) |
Use the form of pointer that accurately reflects the pointer’s ownership rule.
Dramatically fewer opportunities for leaks.
Back to exception safety - What is exception safety?
It is not
- exceptions never happen
- all exceptions get handled
It is
- after an exception is handled, the program is not left in a broken or unusable state.
Specifically - 3 levels of exception safety for a function f:
- Basic guarantee - if an exception occurs, the program will be in some valid state
- Nothing is leaked, no corrupted data structures, all class invariants are maintained.
- Strong guarantee - if an exception is raised while executing f, the state of the program will be as it was before f was called.
- No-throw guarantee - f will never throw or propagate an exception
1 | class A { ... }; |
If a.g() throws - nothing has happened yet. OK
If b.h() throws - effects of a.g() must be undone to offer the strong guarantee.
- Very hard or impossible to achieve if g has non-local side effects.
If A::g B::h don’t have non-local side-effects.
copy & swap:
1 | class C { |
Better if swap was no-throw. Recall: copying pointers cannot throw.
Solution: Access C’s internal state through a pointer. (called the pImpl idiom)
Pimpl Idiom(“pointer to implementation”): Access C’s internal state through a pointer.
1 | struct CImpl { |
This implementation provides the strong guarantee.
In general, if A::g or B::h don’t provide any exception safety, then neither does C::f.
Vectors - RAII and Exception Safety
Constructor Delegation
A constructor can call another constructor as a helper.
1 | struct Vec { |
Exception Safety & the STL - vector
Vectors:
- encapsulate a heap allocated array
- follow RAII - when a stack-allocated vector goes out of scope, the internal heap-allocated array is freed.
1 | void f() { |
But
1 | void g() { |
But
1 | void g() { |
vector<c> - owns the objects
vector<cw> - doesn’t own the objects
vector<unique_ptr<c>> - owns the objects
vector<T>::emplace_back - offers the strong guarantee
- if the array is full (i.e. size == cap)
- allocate new array
- copy object’s over (copy constructor)
- delete old array
- if copy constructor throws
- destroy the new array
- old array still intact
- strong guarantee
- if copy constructor throws
But - copying is expensive & the old array will be thrown away.
- wouldn’t moving the objects be more efficient?
- allocate new array
- move the objects over (move constructor)
- swap arrays
- delete old array
If the move constructor offers the no-throw guarantee, emplace_back will use the move constructor. Otherwise, it will use the copy constructor, which may be slower.
So your move operator should provide the no-throw guarantee, and you should indicate that they do:
1 | class C { |
If you know a function will never throw or propagate an exception, declare it no-except - facilitates optimization.
Casting
In C, casting is:
1 | Node n; |
C style casts should be avoided in C++. If you must cast, use the C++ cast.
4 kinds:
static_cast
Sensible casts with well defined semantics.
Ex. float -> int
1 | float f; |
static_cast allows us to down cast: Superclass * -> Subclass
1 | Book *pb = ...; |
reinterpret_cast
unsafe, implementation dependent, “weird” conversions
1 | Student s; |
const_cast
for converting between const & non-const
- the only C++ cast that an cast away const
1 | void g(int *p); // suppose you know that g won't modify *p in the circumstances when f would call g |
dynamic_cast
is it safe to convert a Book * to a Text *?
1 | Book *bp = ...; |
- Depends on whether pb actually points to a Text.
- Better to do a tentative cast - try it and see if it succceeds.
1 | Text *pt = dynamic_cast<Text *>(pb); |
If the cast works (pb actually points at a Text, or a subclass of Text), pt points at the object.
If the cast fails, pt will be nullptr.
1 | if (pt) cout << pt->getTopic(); |
These are options on raw pointers - can they be done on smart pointer?
Yes - static_pointer_cast, dynamic_pointer_cast, etc.
- cast
shared_ptrstoshared_ptrs - Dynamic casting also works with references.
- Text t{…}
- Book &b = t;
- Text &t2 = dynamic_cast<Text&>(b);
Note: dynamic casting only works on classes with at least one virtual methods.
Dynamic reference casting others a possible solution to the polymorphic assignment problem.
1 | Text &Text::operaator=(const Book &other) { |
Is dynamic casting good style?
Example:
1 | void whatIsIt(Book *b) { |
Tightly coupled to the class hierarchy & may indicate bad design.
Why? What if you create a new subclass of book
- You need to update whatIsIt and all functions like it that query for types.
Better: Use virtual methods
Note: Text::operator= doesn’t have this problem (only comparing with your own type, not all types)
Fix whatIsIt?
1 | clcass Book { |
Works by creating an interface function that is uniform across all Book types.
- But what if the interface isn’t uniform across all types in the hiearchy?
Inheritance & virtual methods work well when
- There is an unlimited number of potential specializations of a basic abstraction
- Each following the same interface
What about the opposite case?
- limited number of specialization, all known in advance, unlikely to change
- with possibly different interfaces
In the first case - adding a new subclass - minimal work.
In the second case - adding a new subclass - reworking existing code to use the new interface, but that is fine, because you aren’t expecting to add new subclasses, or you are expecting to do the work.
1 | class Turtle : public Enemy { |
These interfaces aren’t uniform. In this case a new enemy type = new interface + unavailable work. So we could regard the set of Enemy classes as fixed, and maybe dynamic casting on enemies is justified.
But - in this case, maybe inheritance is not the right abstraction mechanism.
If you know that an enemy will only be a Turtle or a Bullet, and you accept that adding new enemy types requires widespread changes anyway, then consider:
1 | import <variant>; |
Discriminating the value:
1 | if (holds_alternative<Turtle>(e)) { |
Extracting the value:
1 | try { |
A variant is like a union, but type_safe. Attempting to store as one type & fetch as another will throw.
If a variant is left uninitialized, the first option in the variant is default-constructed to initialize the variant - compile error it 1st potion not default.
How Virtual Methods Work
1 | class Vec { |
What’s the difference?
1 | Vec v{1, 2}; |
Do they look the same in memory?
1 | cout << sizeof(v) << " " << sizeof(w) << endl; // 8 16 |
First note 8 = space for 2 integers, there’s no space for the f method.
Compiler turns methods into ordinary functions & stores them separately from objects.
Recall:
Book *pb = new (Book/Text/Comic);
pb->isHeavy();
If isHeavy is virtual, choice of version to run is based on the type of the actual object, which the compiler won’t know in advance.
Therefore the correct isHeavy must be chosen at runtime.
For each class with virtual method, the compiler creates a table of functions pointers (the vtable).
Example:
1 | class C { |

Calling a virtual method (At runtime)
- follow
vptrtovtable - fetch pointer to actual method from
vtable - follow the pointer & call the function
Also: Declaring at least one virtual method adds a vptr to the object.
Classes without virtual methods produce smaller objects than if some methods were virtual.
Concretely, how is an object laid out? It is Compiler-depedent.
Why did we put the vptr first in the object and not somewhere else (e.g. last)?
1 | class A{ |
vptr were put at the first because we need to access the vptr to know the type of the object, and putting vptr to the front is easiest for it to be accessed.
BUT:
Multiple Inheritance
A class can inherit from more than one class.
1 | class A{ |
Challenges:
1 | class D: public B, public C{ |
1 | D dobj; |
But if B & C inherit from A, should there be only one A part of D, or two?
- Should B::a & C::a be the same or different?
- What if we want (deadly diamond)
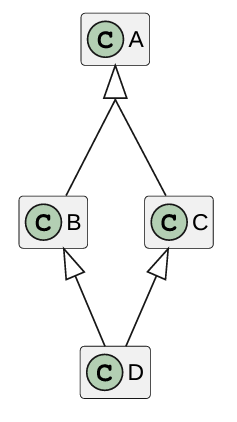
Make A a virtual base class - use virtual inheritance.
1 | class B : virtual public A {...}; |
Example: IO stream library

How will this be laid out
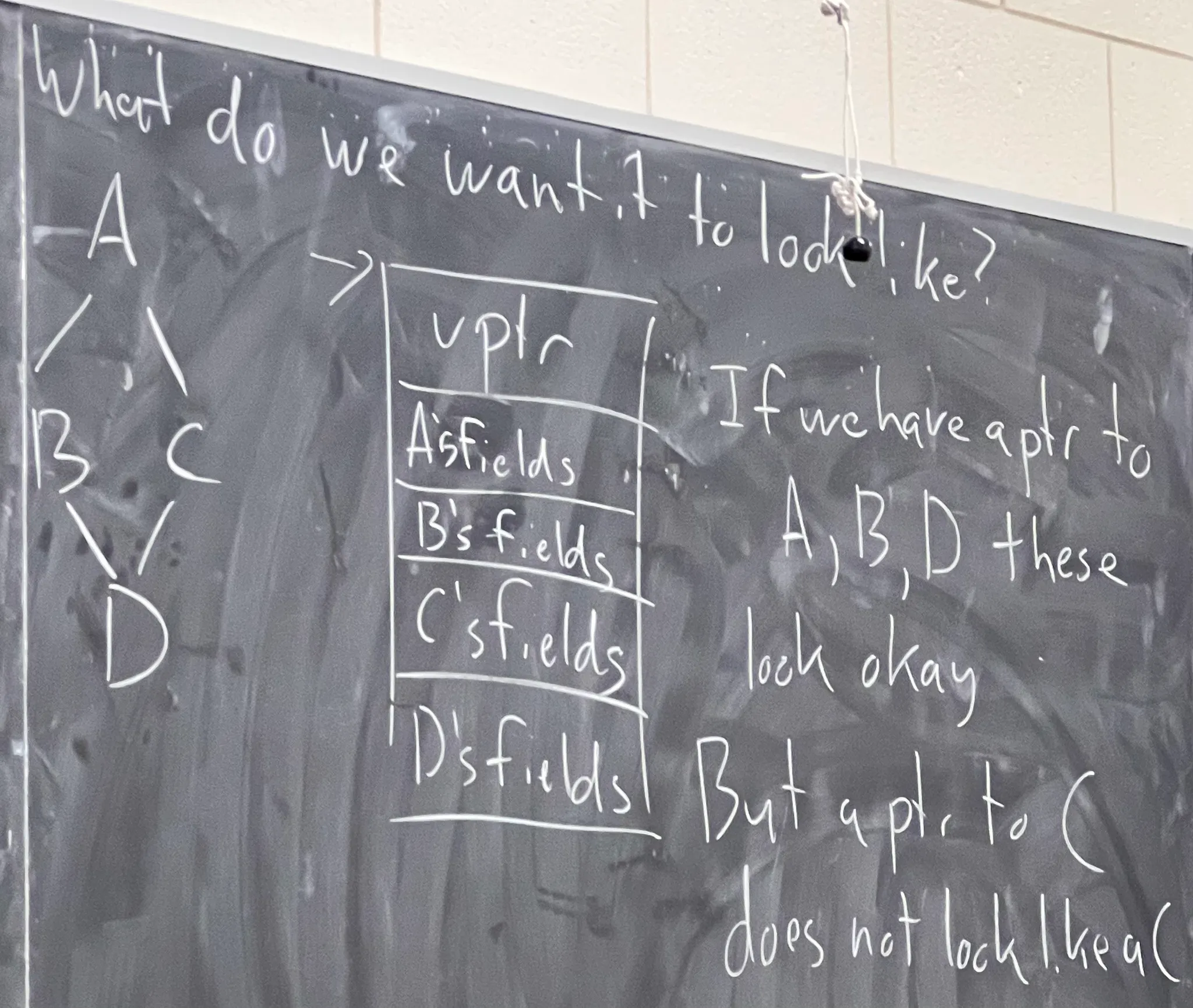

Diagram doesn’t look like all of A, B, C, D.
- but slices of it do look like A, B, C, D.
Therefore pointer assignment among A, B, C, D changes the address shared in the pointer.
1 | D *d = new D{ ... }; |

:max_bytes(150000):strip_icc()/calculus-on-blackboard-79338340-5be4695946e0fb0026d6856f.jpg)


